- Arunima Chaudhary
- Alayt Issak
- et al.
- 2021
- AAAI 2021
AutoAI for text
Scaling AI technologies for NLP and text data to a large variety of users.
Overview
AutoAI for text fills a gap in the area of AutoML technologies by addressing the needs of the many users who have text data and want to quickly build advanced NLP models. AutoAI for Text is a framework that provides both the components and the tools that facilitate the process of NLP model development for text data, via automation, ease-of-use and explainability.
We target users at different levels of skills or expertise, with a particular focus on 1) data scientists who want to quickly get a head start in their text processing projects, and 2) advanced model developers who will want to optimize and fine-tune their models before deployed in production. The goal of AutoAI for Text is to make such users more efficient by reducing model development time and effort while at the same time improving the quality of their models through the use of automatic optimization.
AutoAI for Text starts from the premise that a large space of components is already available, including many types of features (e.g., TFIDF, embeddings), machine learning algorithms (both classical ML and deep learning or DL), as well as pre-existing models (e.g., from customers, from the development teams). However, combining them into feasible pipelines that perform well over a given text dataset and task is a daunting optimization problem, better left for automated algorithms. This is especially challenging in practice when one often has additional constraints that go beyond performance (or accuracy). These constraints may include: the need for explainability, training time budget, inference time constraints, resource availability (e.g., GPUs), and more.
What AutoAI for text provides
AutoAI for Text is a platform that aims to solve the above challenge. This platform combines LALE, a scikit-learn framework for defining and combining types of features and models (including both classical ML and DL models), with specialized operators for deep learning style of backpropagation and batching, and with an optimization layer that performs neural architecture search (NAS), as well as combined algorithm selection and hyperparameter tuning (CASH).
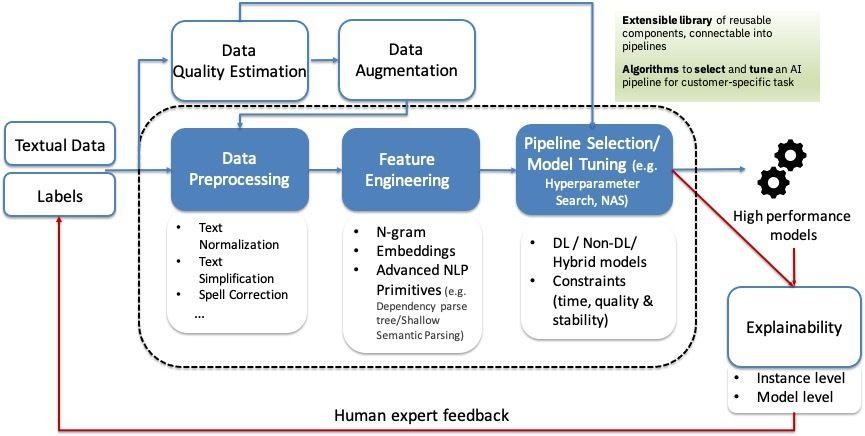
The overall architectural vision of AutoAI for Text is captured conceptually by the following diagram, containing its core elements. At the heart of the system are the three blocks for: 1) data preprocessing, 2) feature engineering and 3) pipeline selection / model tuning, each with a set of capabilities that can be combined, tuned and explored, ultimately leading to the generation of the top pipelines. The data quality estimation and data augmentation blocks offer additional capabilities to understand the characteristics of the dataset and, respectively, to handle class skew in the input data. One of the important blocks (explainability) focuses on presentation of the resulting pipelines and interaction with the human. Explanations can arrive either at the model-level (e.g., when directly intepretable models in the form of rules have been selected) or at the instance-level (i.e., by inspecting the behavior of the model on particular examples).
AutoAI for Text architecture diagram.Value proposition
- AutoAI techniques can automatically assemble new NLP pipelines or fine-tune existing pipelines from users.
- Demonstrated ability to quickly produce state-of-the-art NLP pipelines for sentiment analysis and text classification benchmarks.
- Advanced NLP features range from pre-trained language models to sophisticated syntactic and semantic predicates from Watson NLP.
- Ability to create and optimize neuro-symbolic pipelines that combine neural learning and explainable representations.
- Model introspection at the instance-level with fine-grained error analysis.
Key technologies
- Support for DL & classical ML preprocessors, transformers, estimators
- Higher-order operators for DL backpropagation and batching
- Declarative pipeline composition via a grammar-like syntax
- Advanced NLP primitives from Watson NLP
- Multiple available optimizers (e.g., HyperOpt, Hyperband), supporting NAS and CASH, with time budget constraints
- Ability to built directly interpretable models that combine neural learning and symbolic representations
- Easy-to-use, no programming required front-end for exploring, generating and understanding the top pipelines for a given dataset
- Jupyter notebook interface for more advanced configuration choices including the types of desired models and features, and various optimization parameters

