
- Abhinav Nagpal
- Riddhiman Dasgupta
- et al.
- 2022
- CODS-COMAD 2022
Metadata Management
Overview
Metadata management is an increasingly important area in today’s IT industry. According to Gartner, “Metadata management will become a critical functionality in practically all data-enabling technologies and metadata analytics, augmented and automated design, or even deployment will become the critical foundation of data management platforms.” and “Metadata management will become a critical functionality in practically all data-enabling technologies and metadata analytics, augmented and automated design, or even deployment will become the critical foundation of data management platforms.”
Traditionally, businesses have mostly been content to work with data, and some preliminary metadata around it, but now with the emergence of AI, and its widespread use and everyday success stories, businesses want to get more value out of their data, and metadata plays a key role in there. A good metadata strategy allows businesses to store their data in better way, manage and discover it, and more importantly make the downstream applications produce greater value. One of our daily-life examples showing how metadata can be useful, and how important and challenging it can be to obtain such metadata, is in the context of image search. While until a few years ago, many of us were happy with searching images with simple metadata such as timestamp, size, location, hashtags etc., but now, as the number of images increases, search based on such simple metadata is no longer sufficient. Image-search now needs to be more based on the semantics of the images i.e. based on what the images contain, which is nothing but metadata. One would need to find different entities such as people along with their names and relationships e.g. John, son etc, places along with their characteristics e.g. snow covered mountain, objects along with their attributes e.g. red car, link between different entities e.g. son riding green bike etc. Finding such metadata is extremely challenging and is a research area in itself. One more example of how metadata can be helpful in an enterprise setting would be finding associations between technical metadata i.e., column names and business metadata i.e., business glossary. Similar to semantics in image-search, such associations provide semantics to data in the enterprise which is useful in multiple ways such as data standardization, data search and discovery, removing data redundancy, easier data exchange between different business units, faster data integration etc. Another example of metadata collection and value harvesting would be to collect DB application metadata such as queries executed, their time taken, frequency etc. Such metadata will help one in designing better caching resulting in better query execution time. While these are just the examples of some of the traditional types of metadata, in today's technology world, as the scale and complexity of data increases, and when the world is becoming more and more conscious of the non-functional aspects of data such as data privacy, bias, fair usage, compliance, governance, and at the same time, desire to have access to the data right at their finger tips, the importance of metadata has never been greater. While in industry, metadata often refers to the data about data, its definition is being expanded, to include metadata about other artifacts as well, such as metadata for source code, AI models, infrastructure, business processes, applications etc. A holistic view of metadata including its effective usage and management can go a long way to facilitate and simplify many applications and processes.
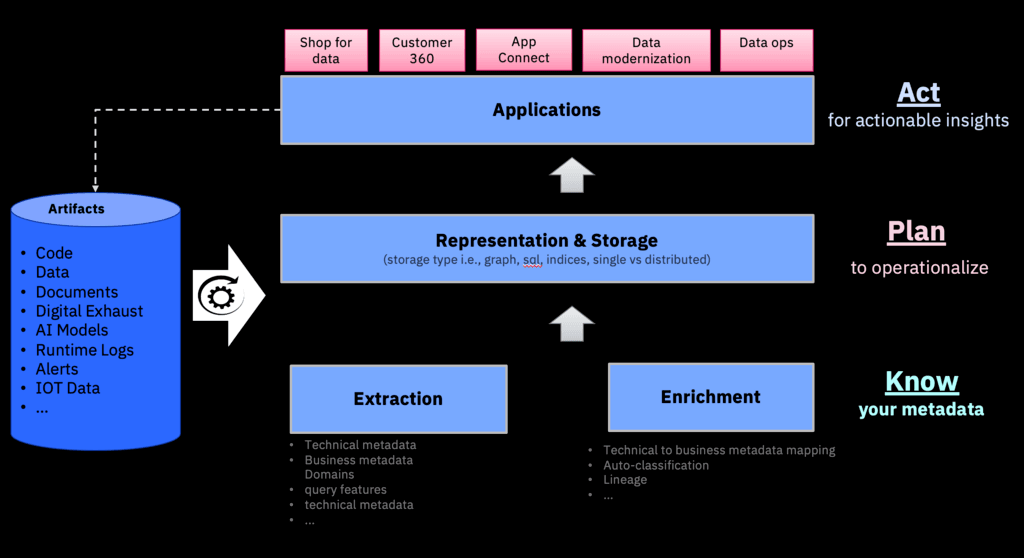
Managing metadata was already a daunting task with the ever increasing amount and complexity of metadata. But now with the emergence of hybrid cloud - where data and thereby metadata is not only physically distributed across different clouds but there are also constraints e.g. security, privacy, regulatory when it comes to one cloud interacting with another - its management is becoming harder and more important than ever. In a hybrid cloud setting, data residing on different clouds needs to be browsed, analyzed, and in general, be treated as one, to deal with challenges such as discovery and reuse of complex and inter-connected information, efficient yet reliable storage, governance and compliance e.g., risk assessment and threat analysis, audits, services and resource governance, quality, provenance, etc. Metadata plays an important role in data management, as addressing many of these challenges do not require one to look at actual data, but can rather be handled based on just metadata. Metadata management includes collecting and storing metadata related to various asset types, and finally, making it available as needed for downstream applications. An effective metadata management system helps you interlink and reuse of existing resources including data, schema, processes, dashboards, AI models; helps explore and discover the right dataset for a particular application; helps you reduce information redundancy and do a better job at governance.
At IBM Research, we focus on various aspects of metadata management including metadata discovery, enrichment, representation and storage, and usage of metadata for better downstream applications. We are working on several exciting research projects including shop for data, governance using metadata, data lineage, customer 360, data quality assessment and remediation, data and AI model testing, data and AI model fairness and explainability, data modernization, and application modernization.
Data Modernization
Here we look at how we can effectively migrate data from one source technology to another e.g., from RDBMS to nosql stores or from legacy systems like VSAM/IMS to RDBMS etc, both independently as well as jointly with application modernization. A migration to a different data store may be required for a number of reasons. For instance, there may be a need to expose business data from existing legacy systems to cloud environments via integration/data fabric, etc., or a need to consolidate, deduplicate and re-organize the data to be better managed and discoverable, or migrate data simply to address skill issues. Data modernization involves various challenges e.g., identifying the right target database technology to migrate to, identifying the right schema on target database, ensuring that all data is migrated without errors, identifying effective microdb specifications etc. Our research is focused on getting a deeper understanding of data landscape on source system based on its metadata e.g., existing schema extraction, discovering rich metadata, understanding data & code interplay, and inferring non-functional characteristics; which is then used for better planning and execution of the data modernization journey.
Governance using Metadata
Here, we primarily work on developing policy manager which enforces the policies residing in Open Policy Agent (OPA) or Watson Knowledge Catalog (WKC). Such a policy manager enables governance officer to create appropriate policies and enforce them at the time of the data access based on the metadata of the asset including transformations such as redaction/removal of sensitive columns.
Master Data Management using Metadata
Metadata management shares a number of capabilities with master data management. Determining if records from different data sources represent the same real world entity, aligning entities to concepts in an ontology, finding links between different entities are some of the master data management capabilities that can be leveraged in Metadata management. We are working on Graph Neural Networks models to enhance these capabilities, and explainability solutions that help Data Stewards to analyze and manage their master data.
Data Lineage
One of our projects on metadata management includes data lineage, a process of understanding, recording, and visualizing data as it flows from data sources to consumption. This includes all transformations the data underwent along the way — how the data was transformed, what changed, and why. Data lineage enables various use-cases like enabling trust and governance in data and AI models, data quality use-cases like track errors in data processes, enable checking for compliance e.g., GDPR, workflow observability etc. We are also developing solutions for tracking data lineage, managing and querying large volumes of lineage data, support various other lineage views e.g., business lineage, column lineage, container lineage etc.
Metadata is already making its way in several IBM products and offerings. For instance, in shop for data, metadata enables self-service data access across any data source, any workload, or any environment for AI, analytics, business intelligence, and applications. Metadata is at the core of multi-cloud data integration that democratizes data for AI, analytics, business intelligence, and applications by automating data integration across hybrid and multi-cloud landscapes. Customer 360 is using metadata to provide a comprehensive view of customers by connecting data across domains. Metadata further automates data governance and privacy to ensure data trust, protection, security, and compliance. We are also using metadata to make the AI more trustworthy by operationalizing AI with governed data integrated throughout the AI lifecycle for trusted outcomes. A list of exciting work continues.
Publications
- 2022
- IAAI 2022
- Vivek Iyer
- Arvind Agarwal
- et al.
- 2021
- EMNLP 2021
- Arvind Agarwal
- Laura Chiticariu
- et al.
- 2021
- NAACL 2021
- 2021
- INFORMS 2021
- Phillipp Müller
- Xiao Qin
- et al.
- 2020
- EDBT 2020
- Himanshu Gupta
- C. Rajmohan
- et al.
- 2020
- Big Data 2020
- Vijay Arya
- Rachel Bellamy
- et al.
- 2020
- JMLR