

- Leonardo G. Azevedo
- Renan Souza
- et al.
- 2020
- First Break
ProvLake
A lineage data management system for tracking data in hybrid cloud deployments.
Overview
ProvLake is a lineage data management system capable of capturing, integrating, and querying data across multiple, distributed services, programs, databases, stores, and computational workflows by leveraging provenance data. It is made for tracking data in hybrid cloud deployments due to its distributed and heterogeneous nature. It is efficient for High-Performance Computing workloads due to its system design principles that aim at attaining very low data capture overhead. ProvLake is highly motivated by its use to support the explainability of the generation of complex Artificial Intelligence models, such as the ones found in Computational Science and Engineering projects, like in the Oil and Gas industry.
ProvLake captures multiworkflow data at runtime to provide for integrated data analysis in heterogeneous, distributed projects. ProvLake logically integrates and ingests multiworkflow data into a provenance database, named ProvLake Data View (PLView), ready for data analyses at runtime. During a multiworkflow execution, the PLView is filled with the following contents: domain data extracted from data stored in multiple stores; explict data relationships datasets distributed across the multiple stores; and the multiworkflow data relationships. The PLView is materialized in a DBMS.
ProvLake provides a lightweight data trackers API to be added to workflow codes, like scripts. Also, a query API is provided for runtime analytical queries that integrate multistore data at runtime. When combined with a polystore, it can query data directly in the multiple stores jointly with their provenance data. ProvLake follows W3C PROV standards for provenance data representation.
System Architecture
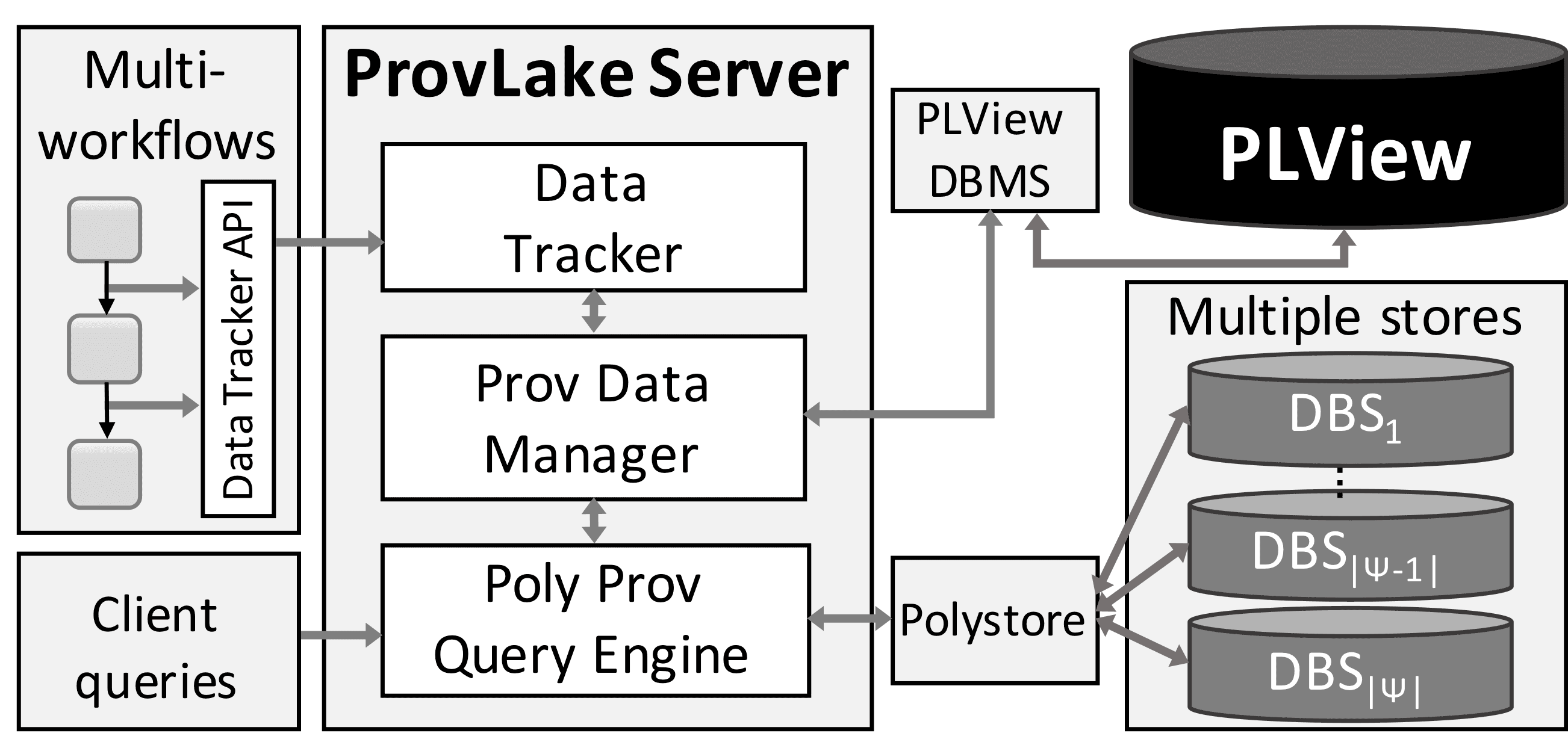
The PLView is the main component and the ProvLake server has three components: ProvCapturer, ProvManager, and PolyProvQueryEngine.
Figure 1. System architecture diagram.To populate the PLView, ProvLake Lib (which encapsulates API calls added to workflow codes) sends data to the ProvCapturer, which receives data coming from the running workflows and transforms into provenance data following ProvLake's data representation which extends W3C PROV-DM. Then, the ProvCapturer sends provenance data to ProvManager which has the connectors to insert data into the DBMS managing the PLView.
To query the PLView, clients send API query requests to PolyProvQueryEngine which connects to ProvDataManager to query the PLView and employs a polystore to query data directly in the multiple stores, jointly with their provenance data.
Implementation details and usage exmaples are provided below for further understanding of ProvLake.
Implementation details
This prototype of ProvLake was evaluated in Python scripts that execute data processing workflows.
ProvLake server components were developed in Python webservers and deployed using Docker images in a Kubernetes cluster. Webservers run on uWSGI for parallel processing of work queues of requests sent to the server at workflow runtime.
ProvLake's data representation is implemented in as an OWL ontology that extends W3C PROV-O, for multi-store data relationships jointly with multi-workflow data dependencies.
The PLView's DBMS is AllegroGraph for analytical graph traversal queries over millions of RDF triples.
The polystore is implemented in PostgreSQL version 11 with Foreign Data Wrappers to MongoDB and AllegroGraph. The polystore uses a global data schema dynamically generated based on a methodology for multi-workflow data design.
Usage examples
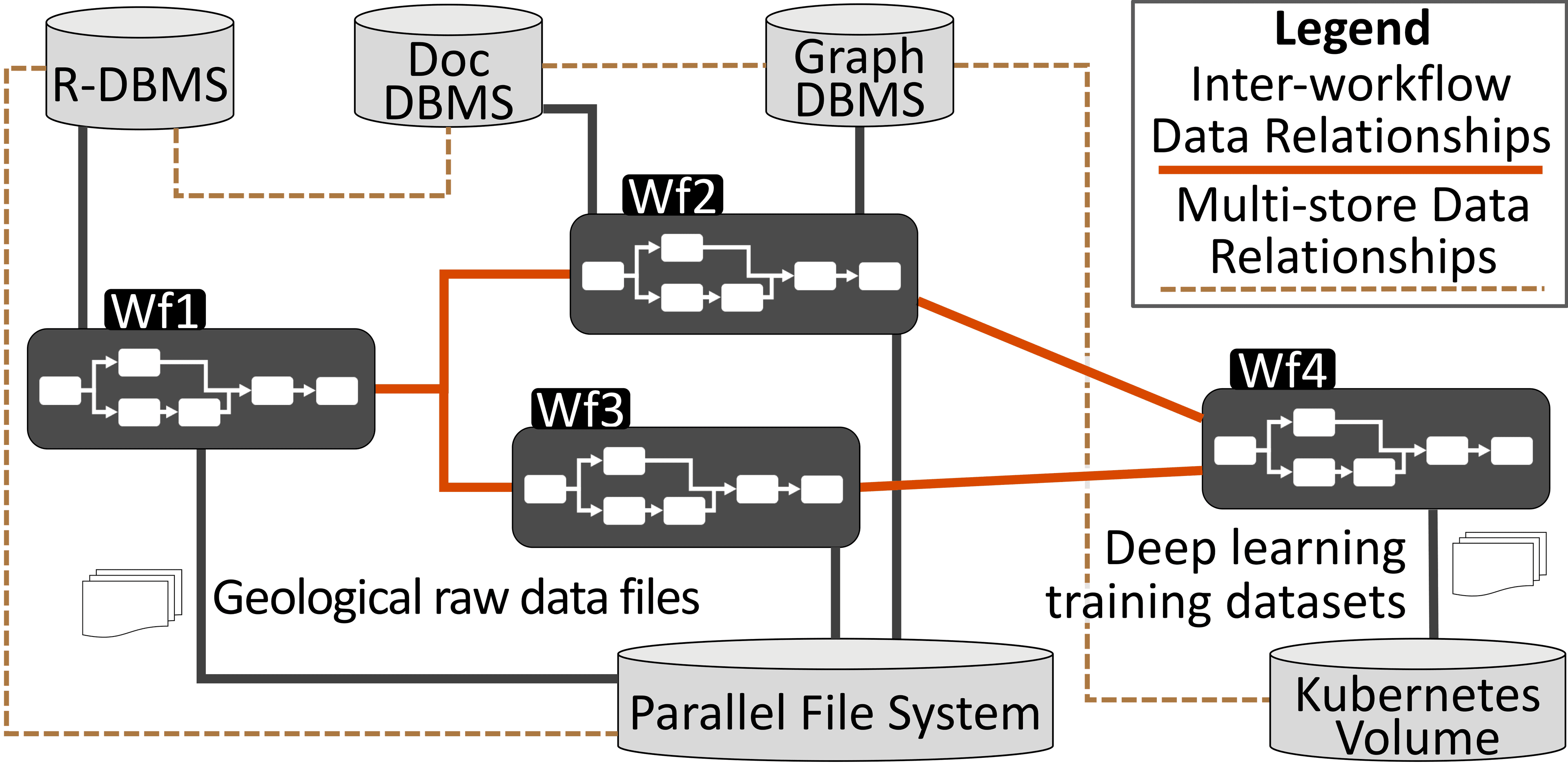
This section presents some examples of ProvLake to preprocess data for a deep learning model for the Oil & Gas domain.
Figure 2. Multiworkflow use case.Figure 3. Deep dive into Workflow 2.Example of Python workflow script with added lightweight API
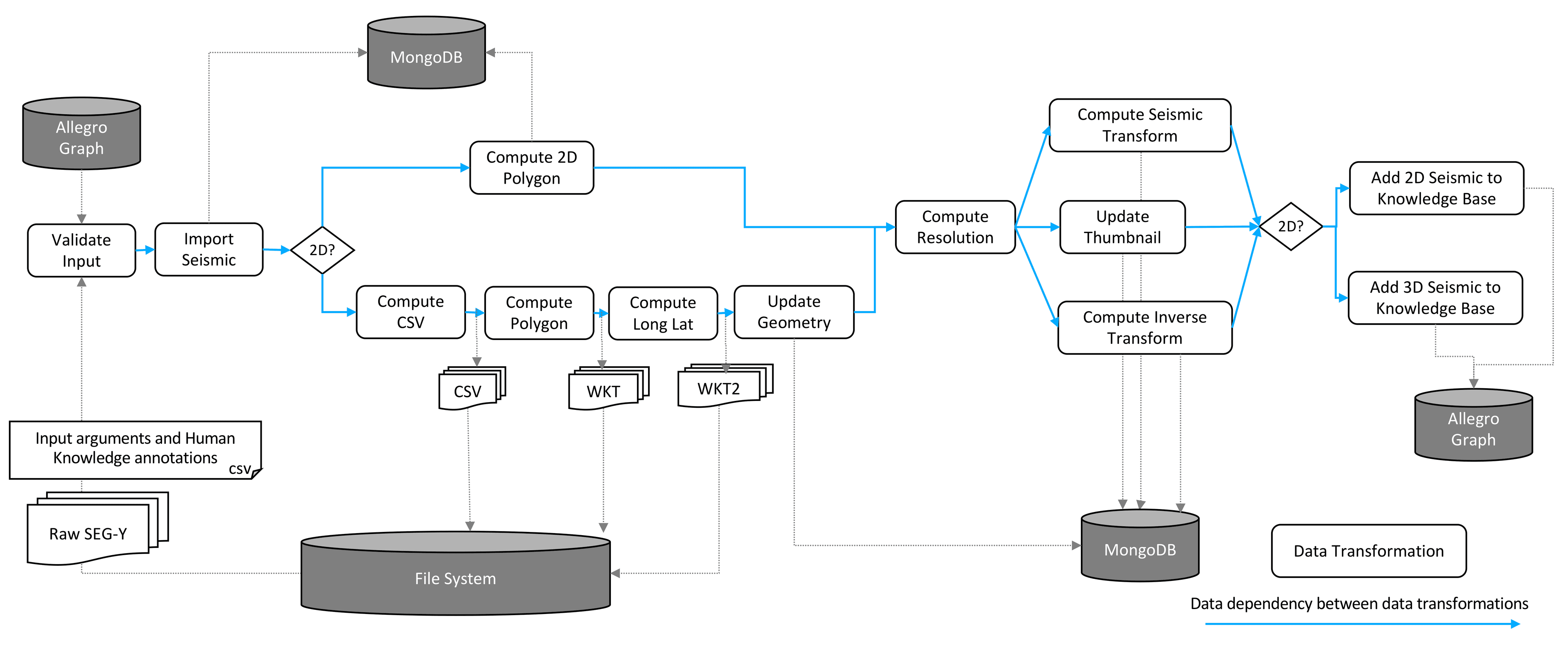
The following lines are a small excerpt of a real Python script of a data processing workflow. The excerpt represents the "Import Seismic" data transformation of the Workflow 2 displayed in the figure above.
- from provlake import ProvLake, DT
- prov = ProvLake(wf_specification_path)
- args = [
- segy_path,
- inline_byte,
- xline_byte,
- geox_byte,
- geoy_byte]
- with DT(prov, "import_seismic", args) as dt:
- document_id = import_seismic(args)
- dt.output(document_id)
- prov.close
Line 10 has a library call that transforms SEG-Y raw data into data in MongoDB, passing the input arguments for the data transformation. The return of this call is a reference to a document in MongoDB representing the raw SEG-Y data.
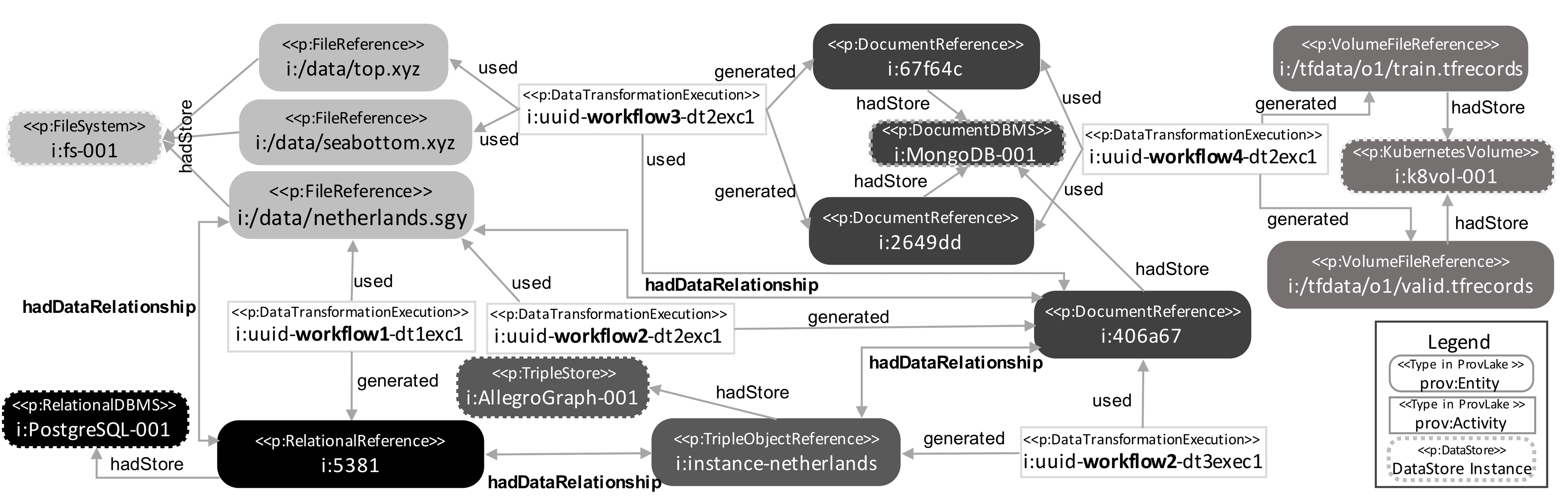
Figure 4. Results of Querying the PLView.Click here to see a larger version of Figure 4.
For the prefixes, “p:” is used for types (they are represented as <
In the figure, we see both the multi-dataflow and multi-database aspects. Grayscale pattern between a database reference attributes and a data store (represented as prov:Entities with a dashed stroke in the figure) is used to illustrate the hadStore relationship. All database reference attributes that are in a same data store follow the background color of the data store instance. To illustrate, during an execution of a data transformation in Workflow 1, ProvLake registered that the data transformation used a seismic raw file (netherlands.sgy), extracted data from it (not shown in the figure), and generated an instance in a relational table, which is stored in PostgreSQL (represented as i:PostgreSQL-001 in the figure). In addition, ProvLake also creates relationships between i:PostgreSQL-001 and the database reference attributes with their corresponding values, and stores the hadDataRelationship relationship between the seismic file and the instance in the relational table. Similarly, when Workflows 2—4 execute, ProvLake tracks domain data values extracted from the data stores, parameters, output values from data transformations, the database reference attributes, and creates the relationships among data references with hadDataRelationship. Then, given the PLView generated during the execution of the multi-workflow, to answer queries PolyProvQueryExecutor executes predefined parametrized graph traversal data analytical query on the PLView contents jointly with the polystore.
PROVLake Provenance Data Representation
ProvLake's provenance data representation follows the PROV-DM standards. It also inherits concepts from background work on representing workflow provenance [1,2,3,4].
Similarly to background work [1,2,3], we separate the data representation into prospective (white background) and retrospective provenance (gray background). <
Prospective Provenance
The OWL file of the ontology is available here.
Starting point
A Project has many Workflows, where each has many Data Transformations. Each Data Transformation has many Attributes, which can be either input or output attributes, depending on whether the attributes are used (input) or generated (output) by the Data Transformation.
Attributes and Schemas
DataSchemas are used to group attributes that semantically belong to a same data representation. For example, {givenName, familyName} are two attributes that belong to a same DataSchema named Person.
One Schema can inherit from another schema, e.g., File and SeismicFile. It is represented by specializationOf relationship.
Thus, Attributes can be part of a DataSchema, which can be part of a DatabaseSchema, which can be part of a Database, which are stored in a DataStore. DataStores have a type property to determine if it is a FILE_SYSTEM, or RELATIONAL_DBMS, or DOCUMENT_DBMS, etc., depending on the data stores in use by the multiworkflow.
An Attribute may not be associated to any Data Schema if grouping attributes is not required when modeling the application data. For example, filePath is an attribute that may not be associated to any DataSchema. In this case, filePath can be directly associated to a DataStore whose type is FILE_SYSTEM.
An Attribute may be simple, list or dicitonary. A simple Attribute is one that is not subdivided. A list is a complex attribute, and we use hadMember relationship to represent that composition. Besides, we also store the order of elements in the list. A dictionary is an Attibute that is composed by other attributes without an order. We are also using hadMember to represent that.
An attribute in a schema can be equivalent to another attribute in another schema, even in different data stores. For instance, attribute "name" of an entity can be stored in different data stores, even with different spelling, but they have the same meaning. We are using alternateOf self-relationship to represent equivalence semantics.
Schemas and Identifiers
DataSchemas have identifying attributes. An attribute or a set of attributes may uniquely identify a record (e.g., tuple in RDBMSs, a document in a Doc DBMS, a resource in a RDF DBMS, a file in a file system) in a data collection (e.g., a table in a RDBMS, a collection in a Doc DBMS, a class in a RDF DBMS, a collection of files in a file system). In this case, an Identifier has one (in case of simple identifiers) or more (if case of composite identifiers) attributes. For example, one can model a DataSchema named Person with attributes {socialSecurityNumber, givenName, familyName} and, in this case, there is an identifier instance with one attribute, socialSecurityNumber.
Relationships between identifiers
Analogously to foreign keys in relational schema modeling, in ProvLake's provenance representation, an attribute that is part of an IdentifierSet may refer (referred relationship) to other attributes that are also part of another IdentifierSet, even if they belong to different schemas (and data stores). This to keep the relationship between data in multiple stores.
Retrospective Provenance
Data Transformation Execution and Attribute Values When a data transformation executes, it uses (as input) attribute values and generates (as output) attribute values.
Some attributes can be stored in DataStoreInstances. DataStoreInstance are specialized into Relational DBMS, Document DBMS, KeyValue Store, FileSystem, etc., depending on the data stores in use by the multiworkflow. Each specialized class has specific properties for specific stores.
Figure 5. Restrospecitve provenance.Click here to see a larger version of Figure 5.
General
We are using prov to present a description of an entity.
Disclaimer
This is a work in progress. We are evolving this data representation as the project evolves.
PROV-ML
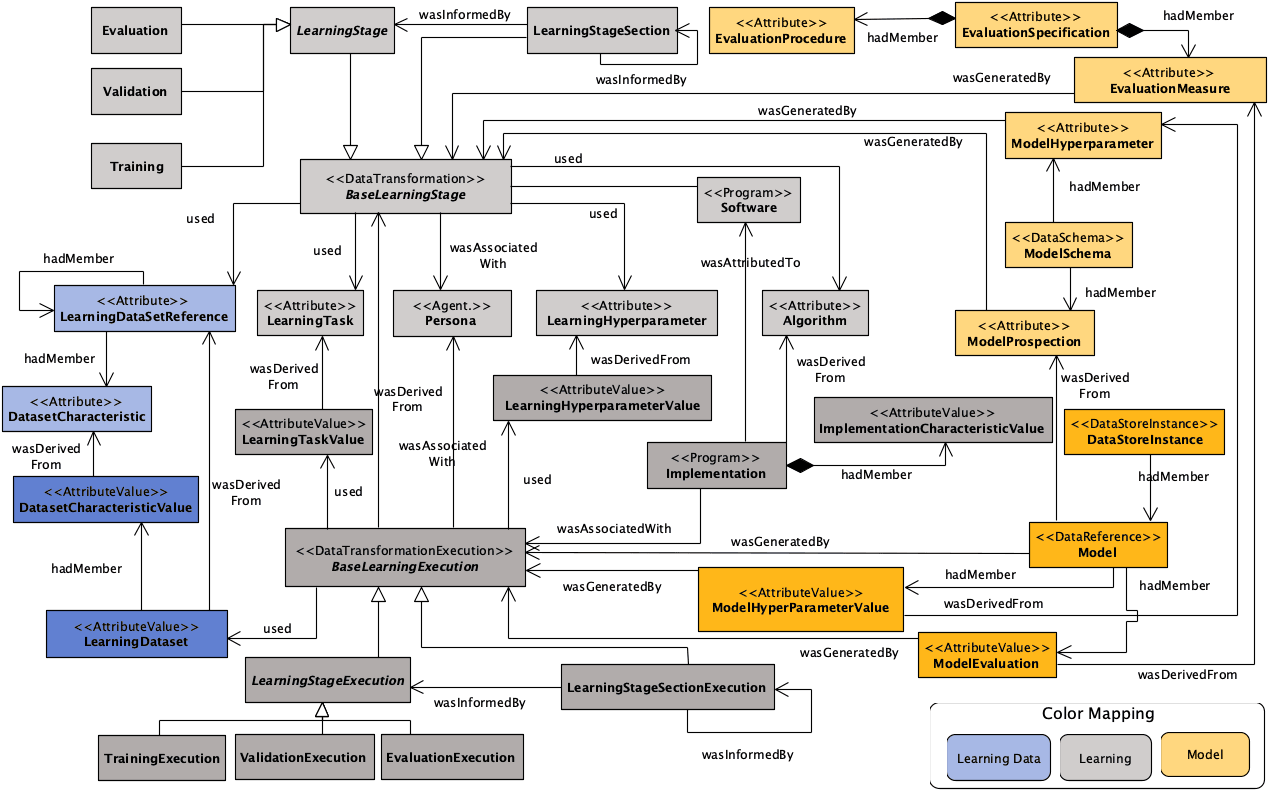
PROV-ML is a W3C PROV- and W3C MLS-compliant data representation for Machine Learning. PROV-ML is depicted in Figure 6 (below), using a UML class diagram, where the light-color classes represent prospective provenance, and dark-color, retrospective.
Figure 6. PROV-ML: a W3C PROV- and W3C ML Schema-compliant workflow provenance data representation.Click here to see a larger version of Figure 6. The colors in the figure map to these concepts: the blue-shaded classes account for the Learning Data; the gray-shaded, for the Learning; and the yellow-shaded, for the Model. The stereotypes indicated in the figure represent the classes inherited from PROVLake. All classes illustrated in the figure are individually described in Table~\ref{tab.
In PROV-ML, the Study class introduces a series of experiments, portrayed by the LearningExperiment class, which defines one of the three major phases in the lifecycle, the Learning phase. A learning experiment comprises a set of learning stages, represented by the BaseLearningStage class, which are the primary data transformation within the Learning phase and with whom the agent (Persona class) is associated.
The base learning stage serves as an abstract class where the LearningStage and LearningStageSection classes inherit from. Also, it relates the ML algorithm, evoked through Algorithm class, used in the stage might be defined in the context of a specific ML task (e.g., classification, regression), represented in the LearningTask class. This approach favors both the learning stage and learning stage section to conserve the relationships among other classes while grant them to have special characteristics discussed in the following. A learning stage varies regarding its type, i.e., Training, Validation, and Evaluation classes. The provision of a specific class for the learning stage allows the explicit representation of the relationship between the Learning Data Preparation phase, through its Learning Data, and the Learning phase of an ML lifecycle. The LearningStageSection class introduces the sectioning semantics that grant capabilities of referencing subparts of the learning stage and the data, respectively. An example of sectioning elements relevance is the ability to reference a specific epoch within a training stage, or mentioning a set of batches within a specific epoch. The Learning Data appears in the model over the LearningDataSetReference class. Another data transformation specified in PROV-ML is the Feature Extraction class, which represents the process that transforms the learning dataset into a set of features, represented by FeatureSet class. This modeling favors the ML experiment to be reproducible since it relates the dataset with the feature extraction process and the resulting feature set.
Further fundamental aspects regarding the Learning phase are the outputs and the parametrization used to produce these outputs. Like so, The ModelSchema class describes the characteristic of the models produced in a learning stage or learning stage section, such as the number of layers of a neural network or the number of trees in a random forest. The ModelProspection class represents the prospected ML models, \ie{ the reference for the ML models learned during a learning stage or learning stage section of a training stage. In addition to the data produced in the Learning phase is the EvaluationMeasure class. This class, combined with EvaluationProcedure and EvaluationSpecification classes, provide the representation of evaluation mechanisms of the produced ML models during any stage of learning, specifically: an evaluation measure defines an overall metric used to evaluate a learning stage (e.g., accuracy, F1-score, area under the curve); an evaluation specification defines the set of evaluation measures used in the evaluation of learned models; and, an evaluation procedure serves as the model evaluation framework, i.e., it details the evaluation process and used methods. On the parametrization aspect, PROV-ML afford two classes LearningHyperparameter and ModelHyperparameter. The first hyperparameter-related class represents the hyperparameter used in a learning stage or learning stage section (e.g., max training epochs, weights initialization). The second class is used in the representation of the models' hyperparameters (e.g., network weights). Finally, PROV-ML addresses the retrospective counterpart of the classes mentioned above. The classes ending in Execution and Value are the derivative retrospective analogous of data transformations and the attributes, respectively.
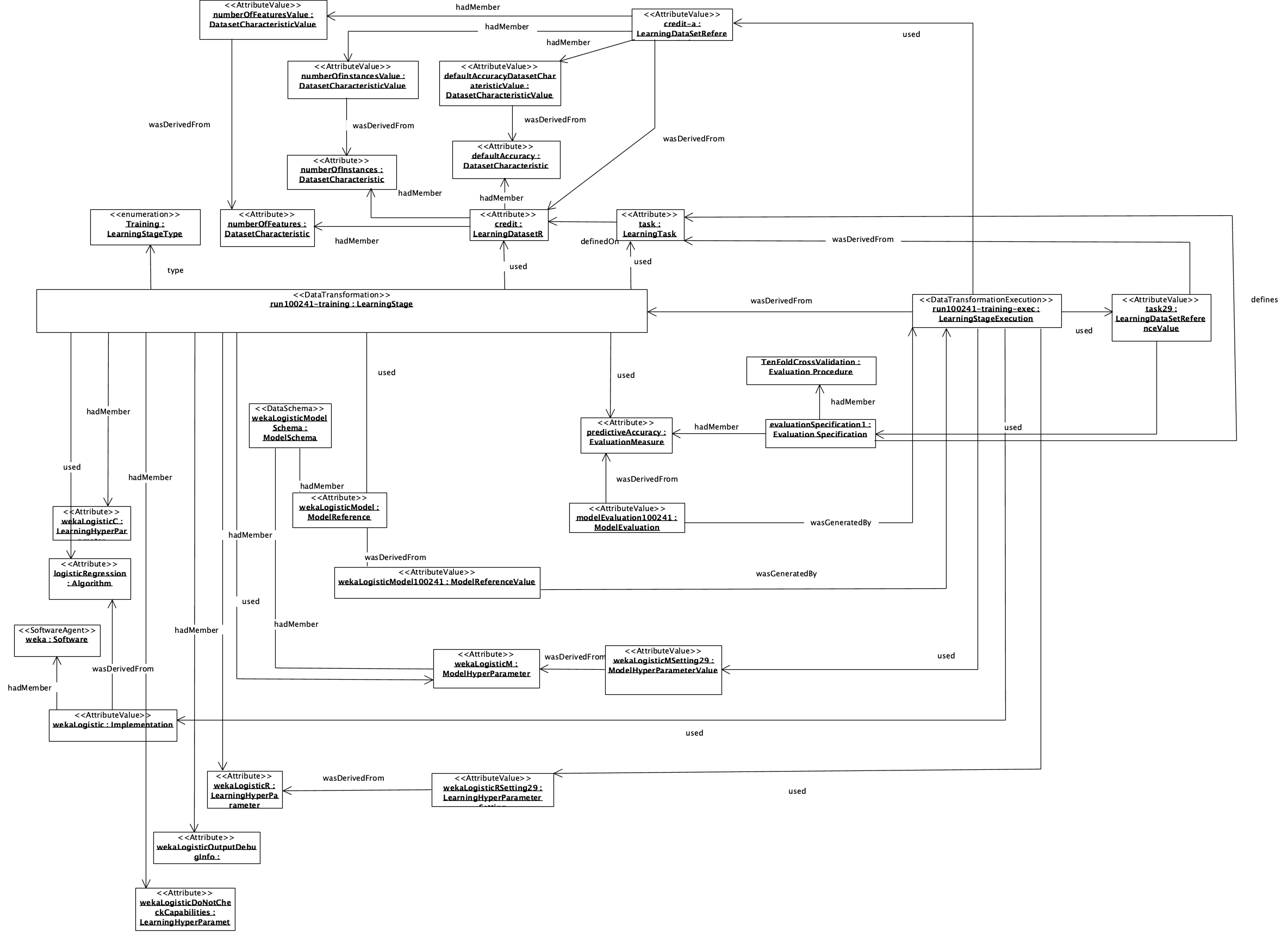
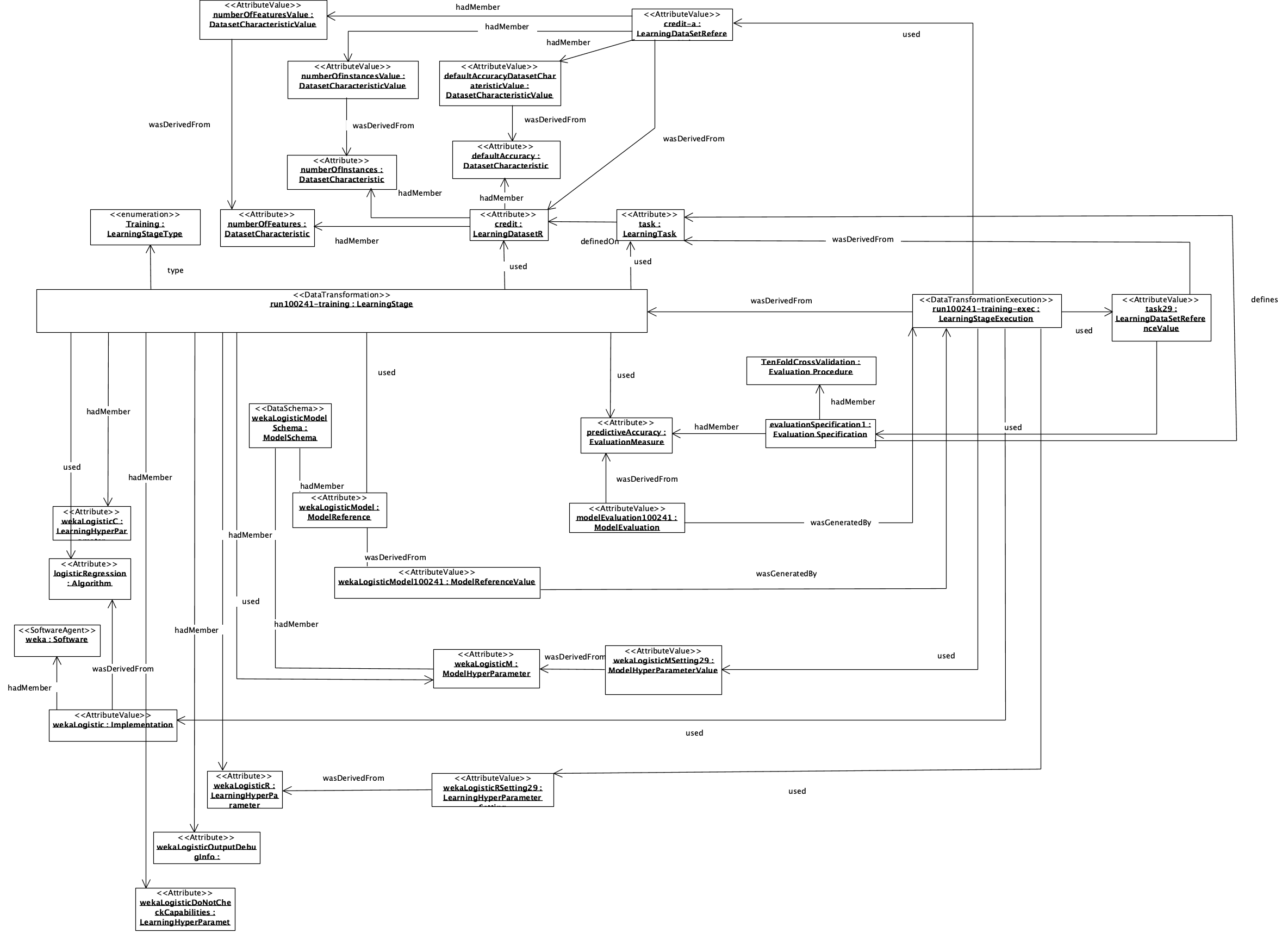
Figure 7 presents an object diagram corresponding to the same example used to illustrate W3C-ML model. The example is derived from the OpenML portal. Some elements were created due to not exist in the example. The example describes entities involved to model a single run of the implementation of a logistic regression algorithm from a Weka machine learning environment. The referenced individuals can easily be looked up online. For instance, run 100241 can be found on http://www.openml.org/r/100241.
Figure 7. PROV-ML object diagram example.Click here to see a larger version of Figure 7.
A demo of PROV-ML was presented at the 2019 IBM Colloquium in Artificial Inteligence. We make available the presentation and the Jupyter ouptut.
Resources
Open Source ProvLakePy is open source: https://github.com/IBM/multi-data-lineage-capture-py
Exemplary SPARQL Queries using PROVLake and PROV-ML Ontologies
- q1.provlake.sparql
- q1.provml.sparql
- q5.provlake.sparql
- q5.provml.sparql
- q7.provlake.sparql
- q7.provml.sparql
OWL Files for the Ontologies: PROVLake Ontology: PROVLake.owl
References
- Souza, R. et al. Efficient Runtime Capture of Multiworkflow Data Using Provenance. in 2019 15th International Conference on eScience (eScience) 359–368 (2019).
- Costa, F. et al. Capturing and querying workflow runtime provenance with PROV: a practical approach. in Proceedings of the Joint EDBT/ICDT 2013 Workshops 282–289 (Association for Computing Machinery, 2013).
- Silva, V. et al. Raw data queries during data-intensive parallel workflow execution. Future Generation Computer Systems 75, 402–422 (2017).
- Souza, R. & Mattoso, M. Provenance of Dynamic Adaptations in User-Steered Dataflows. in Provenance and Annotation of Data and Processes (eds. Belhajjame, K., Gehani, A. & Alper, P.) 16–29 (Springer International Publishing, 2018).
- Souza, R et al. Provenance Data in the Machine Learning Lifecycle. in Computational Science and Engineering Workflows in Support of Large-Scale Science (WORKS) workshop co-located with the ACM/IEEE International Conference for High Performance Computing, Networking, Storage, and Analysis (SC), 2019
- PROV-DM: The PROV Data Model. https://www.w3.org/TR/prov-dm/
- W3C Machine Learning Schema (MLS). http://ml-schema.github.io/documentation/ML%20Schema.html
Publications
- Raphael Thiago
- Renan Souza
- et al.
- 2020
- EAGE Digital 2020
- Renan Souza
- Marta Mattoso
- et al.
- 2019
- eScience 2019
- Renan Souza
- Patrick Valduriez
- et al.
- 2019
- WORKS 2019
- Renan Souza
- Andres Codas
- et al.
- 2020
- ACE 2020
- Renan Francisco Santos Souza
- Leonardo Guerreiro Azevedo
- et al.
- 2021
- CCPE
- Renan Francisco Santos Souza
- Emilio Ashton Vital Brazil
- et al.
- 2019
- ACE 2019
- Leonardo Guerreiro Azevedo
- Renan Francisco Santos Souza
- et al.
- 2020
- SBSI 2020







{kind=link}
{kind=link}
{kind=link}
{kind=link}